Everything about Rregular Expression¶
What is regex¶
Regex solve this problems:
Q:
Does this string match the pattern?A:
match -- find something from the beginning of the string, and return itQ:
Is there a match for the pattern anywhere in this string?A:
search -- find something anywhere in the string, and return itA picture is worth a thousand words
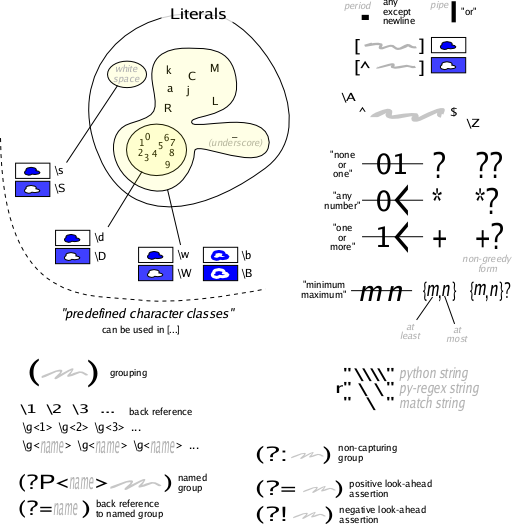 regx-picture
regx-picture
Methods and Attribute¶
| Method/Attributes | Purpose |
|---|---|
match() |
Determine if the RE matches at the beginning of the string. |
search() |
Scan through a string, looking for any location where this RE matches. |
findall() |
Find all substrings where the RE matches, and returns them as a list. |
finditer() |
Find all substrings where the RE matches, and returns them as an iterator. |
| Method/Attributes | Purpose |
|---|---|
group() |
Return the string matched by the RE |
start() |
Return the starting position of the match |
end() |
Return the ending position of the match |
span() |
Return a tuple containing the (start, end) positions of the match |
| Method/Attributes | Purpose |
|---|---|
split() |
Split the string into a list, splitting it wherever the RE matches |
sub() |
Find all substrings where the RE matches, and replace them with a different string |
subn() |
Does the same thing as sub(), but returns the new string and the number of replacements |
Example¶
import re
m = re.match(r'\d+', '123abc')
if m:
print('yep match it')
else:
print('Ops No match')
s = re.search('r\w+@\w+', 'you@me')
# Compile pattern first
pattern = re.compile(r'[\w-@]+')
mp = pattern.match('we@me')
sp = pattern.search('you')
def is_valid_email(string):
email_pattern = re.compile(r'[^@]+@[^@]+\.[^@]+')
return True if email_pattern.match(string) else False
def test_is_valid_email():
assert is_valid_email('abc-123@gmail.com')
assert not is_valid_email('abc@')
# Greedy vs. Non-Greedy
>>> re.match(r'<.*>', '<html>abc</html><a>happy</a>').group() # greedy
>>> '<html>abc</html><a>happy</a>'
>>> re.match(r'<.*?>', '<html>abc</html><a>happy</a>').group() # non-gready
>>> '<html>'